The internet is loaded with data waiting to be extracted. Web scraping is data scraping used for extracting data from websites. Any content that can be viewed on a webpage can be scraped. Many available Web scraping tools and software automates this task. In this article, I intend to show how one can web scrap data from a lotto archive using python, more specifically the BeautifulSoup library.
Web scrapping is one of the important skill one should learn if one wants to be a data scientist.
The data we're going to extract are from: http://www.lotto-archive.com
The collected data contains 1815 entries. It's now ready for data analysis or machine learning exploitation. Basically, the thing you do in scrapping is the same as what we have done using the three steps. With some added details to guide and make your data extraction efficient and purposeful.
Web scrapping is one of the important skill one should learn if one wants to be a data scientist.
The data we're going to extract are from: http://www.lotto-archive.com
- Importing the necessary libraries
- Extracting the necessary data
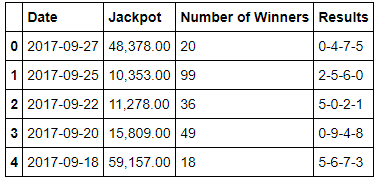
The result of the head of our dataframe. (df.head())
- Saving the extracted data into a file
The collected data contains 1815 entries. It's now ready for data analysis or machine learning exploitation. Basically, the thing you do in scrapping is the same as what we have done using the three steps. With some added details to guide and make your data extraction efficient and purposeful.
- What data do you want and where can you get it.
- Software Workflow:
- Importing the necessary libraries
- Extracting the necessary data
- Saving the extracted data into a file
- What data analysis can you do with the data you have?